

Исходный код:
https://referencesource.microsoft.com/#mscorlib/system/text/stringbuilder.cs,78bad93b62e6340d
Что это, зачем нужно
Что есть строка в C#? Напомню основы. Есть Value, то есть значимые типы данных. И есть Reference, то есть ссылочные типы данных.
Мы привыкли, что «базовые» типы, вроде int, bool, long и подобные — это значимые типы, которые хранятся в стеке (в стандартном сценарии).
Давайте проведем маленький эксперимент.
Вначале посмотрим на то — как себя ведёт int.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
public static void Main() { Console.WriteLine("Int is value type? " + typeof(int).IsValueType); // true var i = 0; Console.WriteLine(i); // 0 Increment(i); Console.WriteLine(i); // 0 IncrementRef(ref i); Console.WriteLine(i); // 1 } private static void Increment(int i) { i = i + 1; } private static void IncrementRef(ref int i) { i = i + 1; } |
Посмотрим как себя будет вести класс
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
public class Test { public string StringValue {get; set;} } public static void Main() { Console.WriteLine("Test is value type? " + typeof(Test).IsValueType); // false var test = new Test(); test.StringValue = "q"; Console.WriteLine(test.StringValue); // q AddLetter(test); Console.WriteLine(test.StringValue); // qq AddLetterRef(ref test); Console.WriteLine(test.StringValue); // qqq } private static void AddLetter(Test t) { t.StringValue = t.StringValue + "q"; } private static void AddLetterRef(ref Test t) { t.StringValue = t.StringValue + "q"; } |
Теперь посмотрим на аналогичную картину со string
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
public static void Main() { Console.WriteLine("String is value type? " + typeof(string).IsValueType); // false var s = "q"; Console.WriteLine(s); // q AddLetter(s); Console.WriteLine(s); // q AddLetterRef(ref s); Console.WriteLine(s); // qq } private static void AddLetter(string s) { s = s + "q"; } private static void AddLetterRef(ref string s) { s = s + "q"; } |
Это ref тип, однако у его поведения есть признаки value-type, что может запутать неопытного разработчика.
Также любые методы, вроде Insert, либо Replace не меняют состояния класса String. Всё правильно — это класс, а не структура. Такие методы, как и операция + пораждают новый экземпляр класса.
Давайте посмотрим на код string.Insert, опустив проверки и оставив только логику:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
public string Insert(int startIndex, string value) { int length1 = this.Length; int length2 = value.Length; if (length1 == 0) return value; if (length2 == 0) return this; string str = string.FastAllocateString(length1 + length2); Buffer.Memmove<char>(ref str._firstChar, ref this._firstChar, (UIntPtr) startIndex); Buffer.Memmove<char>(ref Unsafe.Add<char>(ref str._firstChar, startIndex), ref value._firstChar, (UIntPtr) length2); Buffer.Memmove<char>(ref Unsafe.Add<char>(ref str._firstChar, startIndex + length2), ref Unsafe.Add<char>(ref this._firstChar, startIndex), (UIntPtr) (length1 - startIndex)); return str; } |
Создается новая строка с нужным размером, а затем происходит немного магии по переносу данных.. Но возвращается именно новая строка! А значит, что когда мы в цикле собираем данные в одну строку — мы при каждой итерации порождаем новый экземпляр класса string, который будет висеть в куче и создавать лишнюю работу для Garbage Collector‘а.
И вот мы приходим к тому, что для решения проблемы собирания мусора в памяти нужен инструмент. И разработчики C# его дали — это StringBuilder.
Конструкторы StringBuilder
Их тут аж 6. Но они, в основном, обертки друг над другом.
Первый — без параметров
|
1 2 3 |
public StringBuilder() : this(DefaultCapacity) { } |
Что такое DefaultCapacity? Это числовая константа со значением 16.
|
1 |
internal const int DefaultCapacity = 16; |
Второй — с параметром capacity на вход
|
1 2 3 |
public StringBuilder(int capacity) : this(String.Empty, capacity) { } |
Третий — с параметрами (String value, int capacity)
|
1 2 3 |
public StringBuilder(String value, int capacity) : this(value, 0, ((value != null) ? value.Length : 0), capacity) { } |
Четвертый — со строкой на вход
|
1 2 3 |
public StringBuilder(String value) : this(value, DefaultCapacity) { } |
Пятый — с целыми 4 параметрами на вход:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
public StringBuilder(String value, int startIndex, int length, int capacity) { if (capacity<0) { throw new ArgumentOutOfRangeException("capacity", Environment.GetResourceString("ArgumentOutOfRange_MustBePositive", "capacity")); } if (length<0) { throw new ArgumentOutOfRangeException("length", Environment.GetResourceString("ArgumentOutOfRange_MustBeNonNegNum", "length")); } if (startIndex<0) { throw new ArgumentOutOfRangeException("startIndex", Environment.GetResourceString("ArgumentOutOfRange_StartIndex")); } Contract.EndContractBlock(); if (value == null) { value = String.Empty; } if (startIndex > value.Length - length) { throw new ArgumentOutOfRangeException("length", Environment.GetResourceString("ArgumentOutOfRange_IndexLength")); } m_MaxCapacity = Int32.MaxValue; if (capacity == 0) { capacity = DefaultCapacity; } if (capacity < length) capacity = length; m_ChunkChars = new char[capacity]; m_ChunkLength = length; unsafe { fixed (char* sourcePtr = value) ThreadSafeCopy(sourcePtr + startIndex, m_ChunkChars, 0, length); } } |
Рассмотрим логику — вначале куча проверок и подмена value на string.Empty (если он был null).
Внутри ThreadSafeCopy происходит заполнение массива символов (m_ChunkChars) через string.wstrcpy (об этом как-нибудь в другой раз).
Шестой, последний конструктор, устанавливает capacity и maxCapacity
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
public StringBuilder(int capacity, int maxCapacity) { if (capacity>maxCapacity) { throw new ArgumentOutOfRangeException("capacity", Environment.GetResourceString("ArgumentOutOfRange_Capacity")); } if (maxCapacity<1) { throw new ArgumentOutOfRangeException("maxCapacity", Environment.GetResourceString("ArgumentOutOfRange_SmallMaxCapacity")); } if (capacity<0) { throw new ArgumentOutOfRangeException("capacity", Environment.GetResourceString("ArgumentOutOfRange_MustBePositive", "capacity")); } Contract.EndContractBlock(); if (capacity == 0) { capacity = Math.Min(DefaultCapacity, maxCapacity); } m_MaxCapacity = maxCapacity; m_ChunkChars = new char[capacity]; } |
Состояние класса и константы
Вначале — константы
|
1 2 |
internal const int DefaultCapacity = 16; internal const int MaxChunkSize = 8000; |
Стандартный размер — 16 и максимальный размер чанка — 8000. Вот тут интереснее. Зачем было это делать?
Комментарий разработчиков внутри кода следующий:
We want to keep chunk arrays out of large object heap (< 85K bytes ~ 40K chars) to be sure. Making the maximum chunk size big means less allocation code called, but also more waste in unused characters and slower inserts / replaces (since you do need to slide characters over within a buffer).
Что в переводе:
Мы хотим держать массивы чанков вне LOH (Large Object Heap, об этом в другой статье). Если массив попадёт в LOH, меньше раз будет вызван код на выделение памяти, но вызовы insert’ов и replace’ов будут выполняться медленнее
|
1 2 3 4 5 |
internal char[] m_ChunkChars; // The characters in this block internal StringBuilder m_ChunkPrevious; // Link to the block logically before this block internal int m_ChunkLength; // The index in m_ChunkChars that represent the end of the block internal int m_ChunkOffset; // The logial offset (sum of all characters in previous blocks) internal int m_MaxCapacity = 0; |
| m_ChunkChars | Массив с символами в текущем блоке/чанке. |
| m_ChunkPrevious | Ссылка на предыдущий блок/чанк |
| m_ChunkLength | Индекс окончания блока m_ChunkChars, сколько элементов хранится в этом блоке/чанке |
| m_ChunkOffset | Логический оффсет (сколько символов во всех предыдущих блоках/чанках хранится) |
| m_MaxCapacity | Максимальная вместимость |
Как работает заполнение StringBuilder
По факту тут очень много магии unsafe работы с буферами и строками. Фактически, для понимания, нужно знать следующее — у главного StringBuilder (тот, который мы создаем сами в коде) при его инициализации в последней версии .NET 8 имеет размер равный 16

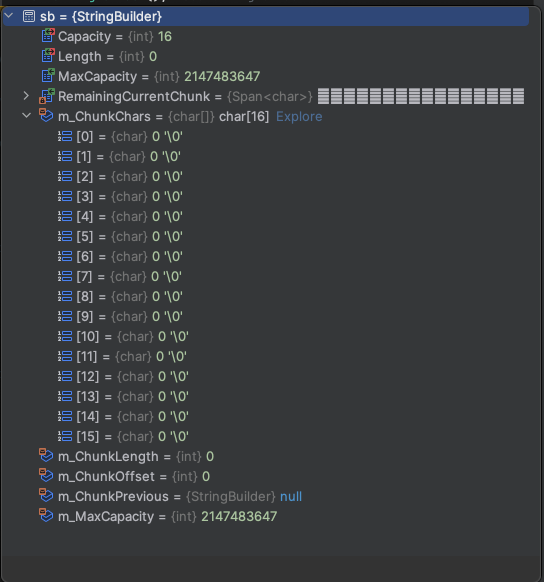
После того, как мы положим в него 256 символов — мы увидим такую картину:

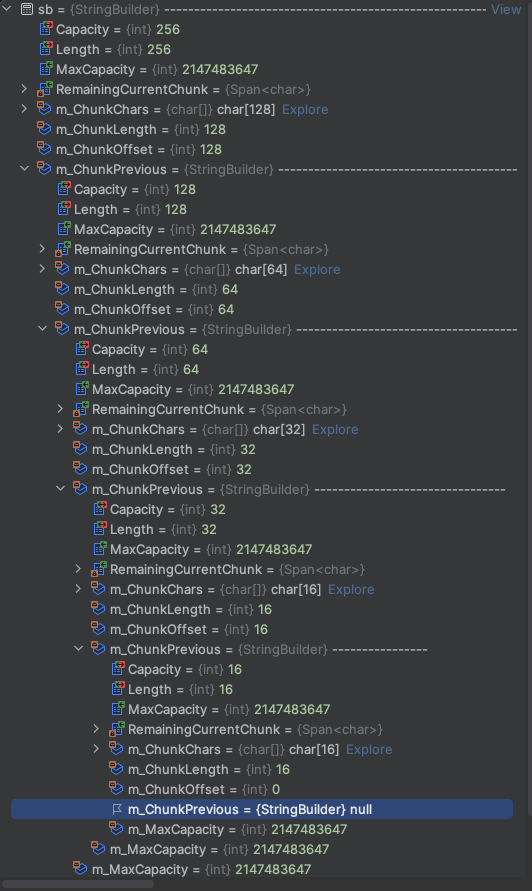
А именно — у родительского (главного) StringBuilder паровозиком прицеплены ещё 4. И тот объект, который мы видели на первом скриншоте (с m_ChunkCapacity = 16 и m_ChunkOffset = 0) — стал последним (в самой глубине списка).
Если идти от самого последнего к первому и смотреть на их m_ChunkCapacity — мы увидим, что имеет место геометрическая прогрессия: 16, 32, 64, 128, 256. А если на размерности массивов m_ChunkChars, то увидим аналогичную прогрессию: 16, 16, 32, 64, 128. Похожую логику мы разбирали уже в C# Особенности работы List.
То есть, если мы не задаём никакой размерности, то по умолчанию — это 16. Когда добавляется 17 символ — появляется новое звено в цепи, но пока тоже на 16 элементов. А вот когда это звено заполнится — пойдет прогрессия и каждое последующее звено будет в 2 раза больше предыдущего. Но не более 8000. Почему? Потому что тут, как и в случае с C# Особенности работы List — разработчики не хотят, чтобы блок попал в LOH (Large Object Heap), работа с которым идёт медленнее.
Давайте проведем эксперимент. Судя по интернету — в романе «Война и Мир» почти 3 миллиона символов. А мы возьмем число ещё больше — половина от int.MaxValue. Попробуем поэксперементировать с этим.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
public static void Main() { var sb = new StringBuilder(); PrintStringBuilderInfo(sb); // 0 / 16 AddCharsToStringBuilder(sb, 16); PrintStringBuilderInfo(sb); // 16 / 16 AddCharsToStringBuilder(sb, 1); PrintStringBuilderInfo(sb); // 17 / 32 AddCharsToStringBuilder(sb, 15); PrintStringBuilderInfo(sb); // 32 / 32 AddCharsToStringBuilder(sb, 32); PrintStringBuilderInfo(sb); // 64 / 64 AddCharsToStringBuilder(sb, int.MaxValue / 2); PrintStringBuilderInfo(sb); // 1073741887 / 1073744192 } private static void AddCharsToStringBuilder(StringBuilder sb, int charsCount) { for (var i = 0; i < charsCount; i++) { sb.Append('-'); } } private static void PrintStringBuilderInfo(StringBuilder sb) { Console.WriteLine(sb.Length + " / " + sb.Capacity); } |

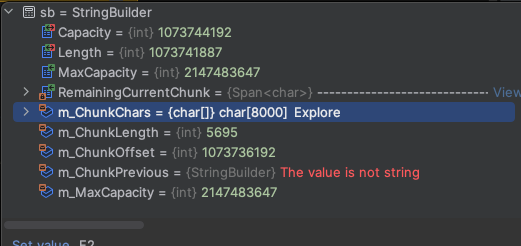
У последнего блока размерность массива равна 8000.
А если, вместо добавления символа в цикле использовать перегрузку метода Append, где есть возможность итерационного добавления?
Обновим код метода:
|
1 2 3 4 |
private static void AddCharsToStringBuilder(StringBuilder sb, int charsCount) { sb.Append('-', charsCount); } |
Вывод остался таким же, но есть интересный нюанс — блоков стало много меньше.. Есть два по 16 символов, один на 32, один на 64.. И один на всё оставшееся. Вот такая подстава.

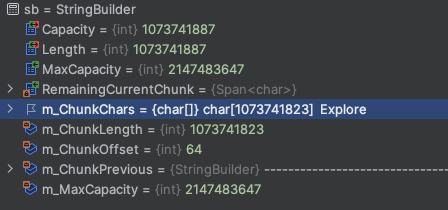
Если попытаться добавить что-нибудь в этот StringBuilder ещё, то он сразу добавить новый блок на 8000 элементов.
Как работает ToString
Вот тут, как раз, всё достаточно просто.
Генерируется строка нужного размера, а затем в неё переносятся все необходимые данные из массива из родительского (основного) StringBuilder по заданному отступу.
Затем по цепочке достаются остальные StringBuilder‘ы и из них уже переносятся данные в строку.
Итого
Конкатенация строк приводит к забиванию мусором кучи, поэтому для решения этой проблемы стоит использовать StringBuilder. Стоит указывать ожидаемый размер строки при инициализации StringBuilder, но не стоит указывать более 8000, иначе первый же созданный блок будет именно заданного вами размера, и он попадёт в Large Object Heap (LOH).
То есть если не указываем ничего (тогда размер будет 16), при ожидаемом размере строки в 100 символов будет создана цепь из 4 блоков. Если укажем более 8000 — попадём в Large Object Heap. Если укажем 8000, но символов будет ожидаемо меньше, то мы выделим 8кб памяти впустую. То есть лучше стараться анализировать и предугадывать потенциальный размер строки.